

[ad_1]
Google’s AVIS program can dynamically select a series of steps to undertake, such as identifying an object in a picture, then looking up information about that object. UCLA, Google
Artificial intelligence programs have dazzled the public with how they produce an answer no matter what the query. However, the quality of the answer often falls short because programs such as ChatGPT merely respond to text input, with no particular grounding in the subject matter, and can produce outright falsehoods as a result.
A recent research project from the University of California and Google instead enables large language models such as Chat-GPT to select a specific tool — be it Web search or optical character recognition — that can then seek an answer in multiple steps from an alternate source.
Also: ChatGPT lies about scientific results, needs open-source alternatives, say researchers
The result is a primitive form of “planning” and “reasoning,” a way for a program to determine at each moment how a question should be approached, and once addressed, whether the solution was satisfactory.
The effort, called AVIS (for “Autonomous Visual Information Seeking with Large Language Models”) by Ziniu Hu and colleagues at the University of California at Los Angeles, and collaborating authors at Google Research, is posted on the arXiv pre-print server.
AVIS is built on Google’s Pathways Language Model, or PaLM, a large language model that has spawned multiple versions adapted to a variety of approaches and experiments in generative AI.
AVIS is in the tradition of recent research seeking to turn machine learning programs into “agents” that act more broadly than simply producing a next-word prediction. They include BabyAGI, an “AI-powered task management system” introduced this year, and PaLM*E, introduced this year by Google researchers, which can instruct a robot to follow a series of actions in physical space.
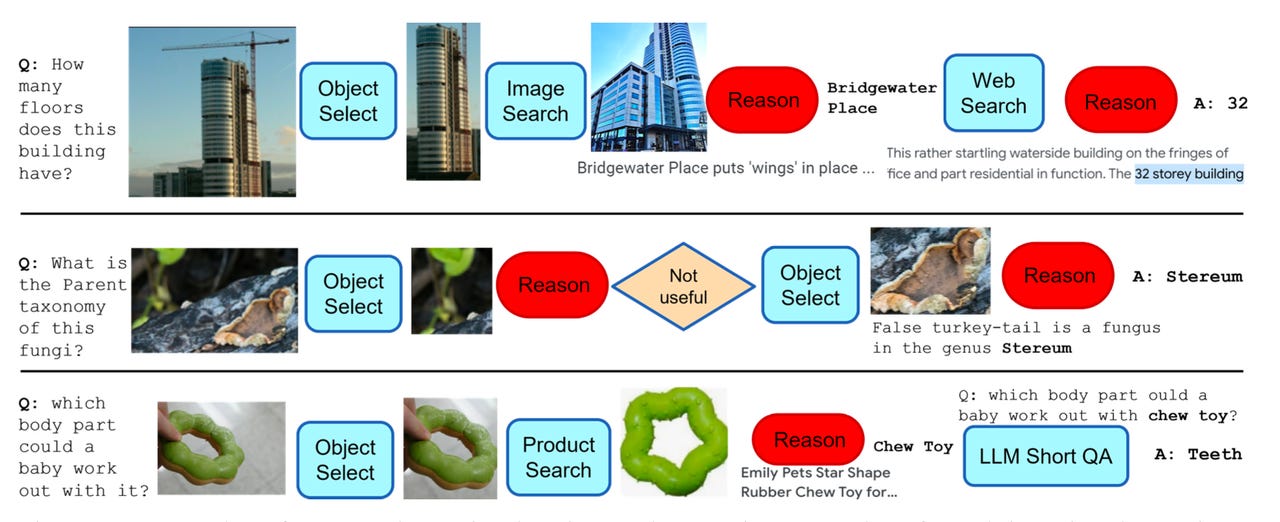
The big breakthrough of the AVIS program is that — unlike BabyAGI and PaLM*E — it doesn’t follow a pre-set course of action. Instead, it uses an algorithm called a “Planner” that selects between a choice of actions on the fly, as each situation arises. Those choices are generated as the language model evaluates the prompted text, breaking it down into sub-questions, and then correlating those sub-questions to a set of possible actions.
Even the choice of actions is a novel approach here.
Also: Google updates Vector AI to let enterprises train GenAI on their own data
Hu and colleagues did a survey of 10 humans who had to answer the same kinds of questions — questions such as “What is the name of the insect?” shown in a picture. Their choices of tools, such as Google Image Search, were recorded.
The authors then put those examples of human choices into what they call a “transition graph,” a model of how humans make choices of tools in each moment.
The Planner then uses the graph, choosing from “relevant in-context examples […] that are assembled from the decisions previously made by humans.” It’s a way to get the program to model itself on humans’ choices, in effect, by using past examples as just more input to the language model.
Also: AI’s multi-view wave is coming, and it will be powerful
In order to act as a check on its choices, the AVIS program has a second algorithm, a “Reasoner,” which evaluates how useful each tool was after it was tried by the language model, before deciding whether to output an answer to the original question. If the particular tool choice was not helpful, the Reasoner will send the Planner back to the drawing board.
The total AVIS workflow consists of devising questions, selecting tools, and then using the Reasoner to check if the tool has produced a satisfactory answer. UCLA, Google
Hu and team tested AVIS on some standard automated benchmark tests of visual question answering, such as OK-VQA, introduced in 2019 by researchers at Carnegie Mellon University. On that test, AVIS achieved “an accuracy of 60.2, higher than most of the existing methods tailored for this dataset,” they report. In other words, the general approach here seems to surpass methods that have been carefully tailored to fit a specific task, an example of the increasing generality of machine learning AI.
Also: Generative AI tops Gartner’s top 25 emerging technologies for 2023
In concluding, Hu and team note that they expect to move beyond just image questions in future work. “We aim to extend our LLM-powered dynamic, decision-making framework to address other reasoning tasks,” they write.
[ad_2]
Source link