

[ad_1]
Deep Learning is probably the most popular form of machine learning at this time. Although not every problem boils down to a deep learning model, in domains such as computer vision and natural language processing deep learning is prevalent.
A key issue with deep learning models, however, is that they are resource hungry. They require lots of data and compute to train, and lots of compute to operate. As a rule, GPUs are known to perform better than CPUs for both training and inference, while some models can’t run on CPUs at all. Now Deci wants to change that.
Deci, a company aiming to optimize deep learning models, is releasing a new family of models for image classification. These models outperform well-known alternatives in both accuracy and runtime, and can run on the popular Intel Cascade Lake CPUs.
We caught up with Deci CEO and co-founder Yonatan Geifman to discuss Deci’s approach and today’s release.
Deep learning performance entails trade-offs
Deci was cofounded by Geifman, Jonathan Elial, and Ran El-Yaniv in 2019. All founders have a background in machine learning, with Geifman and El-Yaniv also having worked at Google. They had the chance to experience first hand how hard getting deep learning into production is.
Deci founders realized that making deep learning models more scalable would help getting them to run better in production environments. They also saw hardware companies trying to build better AI chips to run inference at scale.
The bet they took with Deci was to focus on the model design area in order to make deep learning more scalable and more efficient, thus enabling them to run better in production environments. They are using an automated approach to design models that are more efficient in their structure and in how they interact with the underlying hardware in production.
Deci’s proprietary Automated Neural Architecture Construction (AutoNAC) technology is used to develop so-called DeciNets. DeciNets are pre-trained models that Deci claims outperform known state-of-the-art models in terms of accuracy and runtime performance.
In order to get better accuracy in deep learning, you can take larger models and train them for a little bit more time with a little bit more data and you will get better results, Geifman said. Doing that, however, generates larger models, which are more resource intensive to run in production. What Deci is promising is solving that optimization problem, by providing a platform and tools to build models that are both accurate and fast in production.
Solving that optimization problem requires more than manual tweaking of existing neural architecture, and AutoNAC can design specialized models for specialized use cases, Geifman said. This means being aware of the data and the machine learning tasks at hand, while also being aware of the hardware the model will be deployed on.
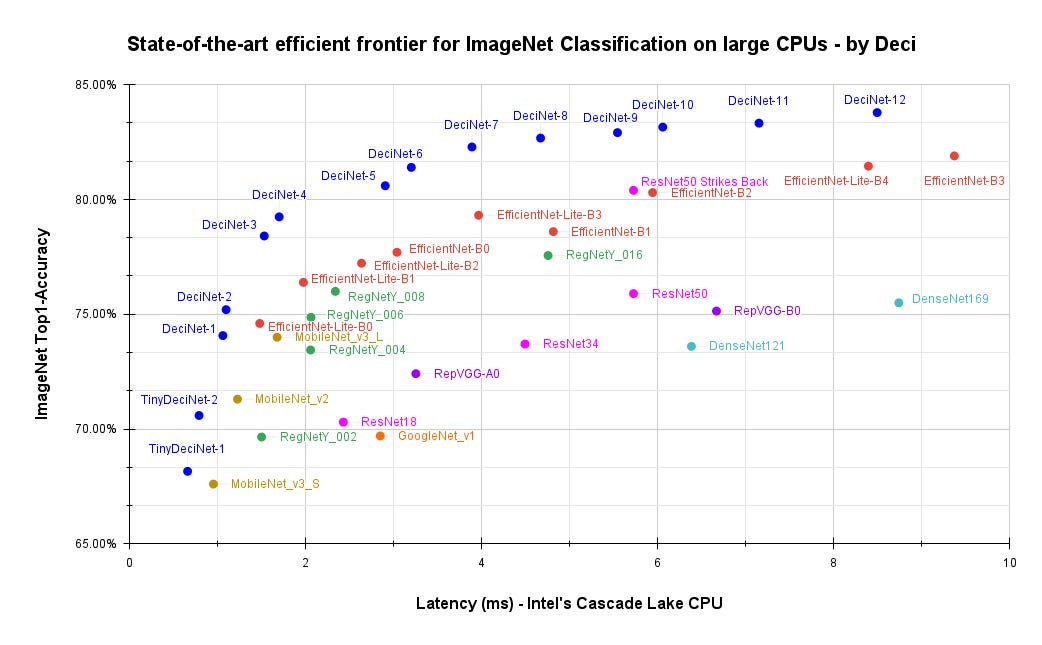
Performance of DeciNets for image classification compared to other deep learning image classification models for Intel Cascade Lake CPUs. Image: Deci
The DeciNets announced today are geared for image classification on Intel Cascade Lake CPUs, which as Geifman noted are a popular choice in many cloud instances. Deci dubs those models “industry-leading”, based on some benchmarks which Geifman said will be released for 3rd parties to be able to replicate.
There are three main tasks in computer vision: image classification, object detection, and semantic segmentation. Geifman said Deci produces multiple types of DeciNets for each task. Each DeciNet aims at a different level of performance, defined as the trade-off between accuracy and latency.
In the results Deci released, variations of DeciNet with different levels of complexity (i.e. number of parameters) are compared against variations of other image classification models such as Google’s EfficientNet and the industry standard ResNet.
According to Geifman, Deci has dozens of models pre-optimized for customers to use in a completely self served offering, ranging from various computer vision tasks to NLP tasks on any type of hardware to be deployed in production.
The deep learning inference stack
However, there is a catch here. Since DeciNets are pre-trained, this means that they won’t necessarily perform as needed for a customer’s specific use case and data. Therefore, after choosing the DeciNet that has the optimal accuracy / latency tradeoff for the use case’s requirements, users need to fine tune it for their data.
Subsequently, an optimization phase follows, in which the trained model is compiled and quantized with Deci’s platform via API or GUI. Finally, the model can be deployed leveraging Deci’s deployment tools Infery & RTiC. This end-to-end coverage is a differentiator for Deci, Geifman said. Notably, existing models can also be ported to DeciNets.
When considering the end-to-end lifecycle, economics and tradeoffs play an important role. The thinking behind Deci’s offering is that training models, while costly, is actually less costly than operating models in production. Therefore, it makes sense to focus on producing models that cost less to operate, while having accuracy and latency comparable to existing models.
The same pragmatic approach is taken when targeting deployment hardware. In some cases, when minimizing latency is the primary goal, the fastest possible hardware will be chosen. In other cases, getting less than optimal latency in exchange for reduced cost of operation may make sense.
For edge deployments, there may not even be a choice to be made: the hardware is what it is, and the model to be deployed should be able to operate under given constrains. Deci is offering a recommendation and benchmarking tool that can be used to compare latency, throughput and cost for various cloud instances and hardware types, helping users make a choice.
Deci is involved in a partnership with Intel. Although today’s release was not done in collaboration with Intel, the benefits for both sides are clear. By working with Deci, Intel expands the range of deep learning models that can be deployed on its CPUs. By working with Intel, Deci expands its go to market reach.

Deci is targeting optimization of deep learning model inference on a variety of deployment targets. Image: Deci
As Geifman noted, however, Deci targets a wide range of hardware, including GPUs, FPGAs, and special-purpose ASIC accelerators, and has partnerships in place with the likes of HPE and AWS too. Deci is also working on partnerships with various types of hardware manufacturers, cloud providers and OEMs that sell data centers and services for machine learning.
Deci’s approach is reminiscent of TinyML, except for the fact that it targets a broader set of deployment targets. When discussing this topic, Geifman referred to the machine learning inference acceleration stack. According to this conceptualization, acceleration can happen at different layers of the stack.
It can happen on the hardware layer, by choosing where to deploy models. It can happen on the runtime / graph compiler layer, where we see solutions provided by hardware manufacturers such as Tensor RT by Nvidia or OpenVino by Intel. We also have the ONNX open source supported by Microsoft, as well as commercial solutions such as Apache TVM being commercialized by OctoML.
On top of that, we have model compression techniques like pooling and quantization, which Geifman noted are are widely utilized by various open source solutions, with some vendors working on commercialization. Geifman framed Deci as working on a level above those, namely the level of neural architecture search, helping data scientists design models to get better latency while maintaining accuracy.
Deci’s platform offers a Community tier aimed at developers looking to boost performance and shorten development time, as well as Professional and Enterprise tiers with more options, including use of DeciNets. The company has raised a total of $30 million in two funding rounds and has 40 employees, mostly based in Israel. According to Geifman, more DeciNets will be released in the immediate future, focusing on NLP applications.
[ad_2]
Source link