

[ad_1]
TikTok owner ByteDance’s “Self-Controlled Memory system” can reach into a data bank of hundreds of turns of dialogue, and thousands of characters, to give any language model capabilities superior to that of ChatGPT to answer questions about past events. ByteDance
When you type things into the prompt of a generative artificial intelligence (AI) program such as ChatGPT, the program gives you a response based not just on what you’ve typed, but also all the things you’ve typed before.
You can think of that chat history as a sort of memory. But it’s not sufficient, according to researchers at multiple institutions, who are trying to endow generative AI with something more like an organized memory that can augment what it produces.
Also: How to use ChatGPT: Everything you need to know
A paper published this month by researcher Weizhi Wang from University of California at Santa Barbara, and collaborators from Microsoft, titled “Augmenting Language Models with Long-Term Memory”, and posted on the arXiv pre-print server, adds a new component to language models.
The problem is ChatGPT and similar programs can’t take in enough text in any one moment to have a very long context for things.
As Wang and team observe, “the input length limit of existing LLMs prevents them from generalizing to real-world scenarios where the capability of processing long-form information beyond a fix-sized session is critical.”
OpenAI’s GPT-3, for example, takes maximal input of 2,000 tokens, meaning, characters or words. You can’t feed the program a 5,000-word article, say, or a 70,000-word novel.
Also: This new technology could blow away GPT-4 and everything like it
It’s possible to keep expanding the input “window,” but that runs into a thorny computing problem. The attention operation — the essential tool of all large language programs, including ChatGPT and GPT-4 — has “quadratic” computational complexity (see the “time complexity” of computing). That complexity means the amount of time it takes for ChatGPT to produce an answer increases as the square of the amount of data it is fed as input. Increasing the window balloons the compute needed.
And so some scholars, note Wang and team, have already tried to come up with a crude memory. Yuhuai Wu and colleagues at Google last year introduced what they call the Memorizing Transformer, which stores a copy of previous answers that it can in future draw upon. That process lets it operate on 65,000 tokens at a time.
But Wang and team note the data can become “stale”. The process of training the Memory Transformer makes some things in memory become out of sync with the neural network as its neural weights, or, parameters, are updated.
Wang and team’s solution, called “Language Models Augmented with Long-Term Memory”, or LongMem, uses a traditional large language model that does two things. As it scrutinizes input, it stores some of it in the memory bank. It also passes the output of every current prompt to a second neural network, called the SideNet.
Also: How I tricked ChatGPT into telling me lies
The SideNet, which is also a language model, just like the first network, is tasked with comparing the current prompt typed by a person to the contents of memory to see if there’s a relevant match. The SideNet, unlike the Memory Transformer, can be trained on its own apart from the main language model. That way, it gets better and better at picking out contents of memory that won’t be stale.
Wang and team run tests to compare LongMem to both the Memorizing Transformer and to OpenAI’s GPT-2 language model. They also compare LongMem to reported results from the literature for other language models, including the 175-billion parameter GPT-3.
They use tasks based on three datasets that involve summarizing very long texts, including whole articles and textbooks: Project Gutenberg, the arXiv file server, and ChapterBreak.
To give you an idea of the scale of those tasks, ChapterBreak, introduced last year by Simeng Sun and colleagues at the University of Massachusetts Amherst, takes whole books and tests a language model to see if, given one chapter as input, it can accurately identify from several candidate passages which one is the start of the next chapter. Such a task “requires a rich understanding of long-range dependencies”, such as changes in place and time of events, and techniques including “analepsis”, where, “the next chapter is a ‘flashback’ to an earlier point in the narrative.”
Also: AI is more likely to cause world doom than climate change, according to an AI expert
And it involves processing tens or even hundreds of thousands of tokens.
When Sun and team ran those ChapterBreak tests, they reported last year, the dominant language models “struggled”. For example, the large GPT-3 was right only 28% of the time.
But the LongMem program “surprisingly” beat all the standard language models, Wang and team report, including GPT-3, delivering a state-of-the-art score of 40.5%, despite the fact that LongMem has only about 600 million neural parameters, far fewer than the 175 billion of GPT-3.
“The substantial improvements on these datasets demonstrate that LONGMEM can comprehend past long-context in cached memory to well complete the language modeling towards future inputs,” write Wang and team.
The Microsoft work echoes recent research at ByteDance, the parent of social media app TikTok.
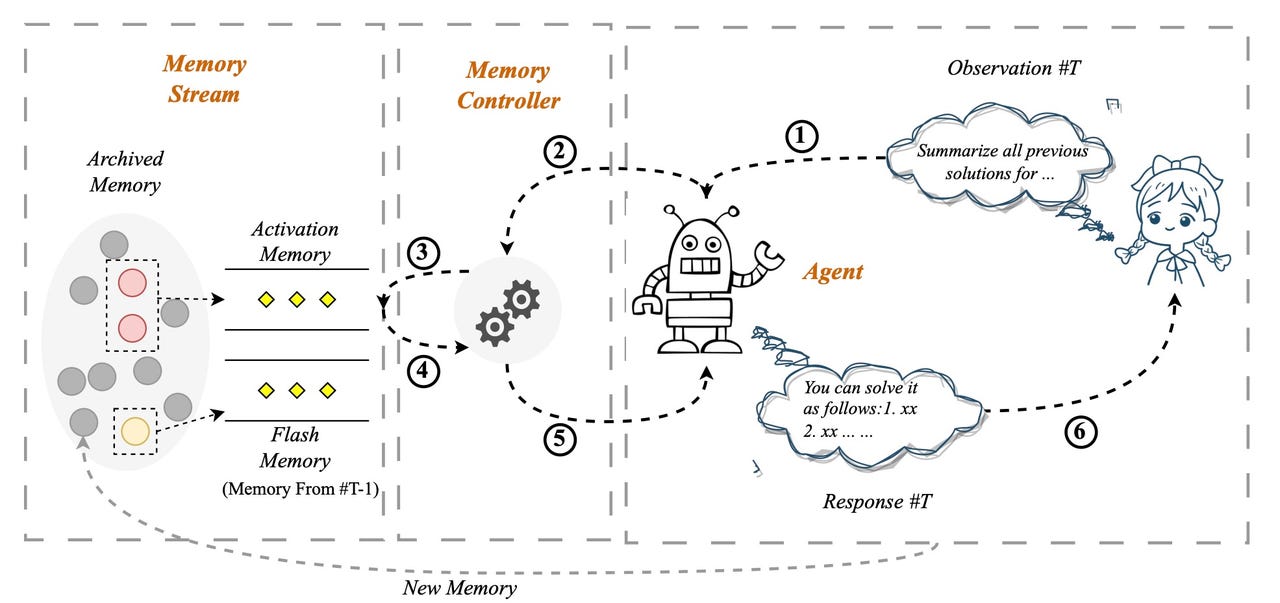
In a paper posted in April on arXiv, titled “Unleashing Infinite-Length Input Capacity for Large-scale Language Models with Self-Controlled Memory System”, researcher Xinnian Liang of ByteDance and colleagues developed an add-on program that gives any large language model the ability to store very long sequences of stuff talked about.
Also: AI will change software development in massive ways, says MongoDB CTO
In practice, they contend, the program can dramatically improve a program’s ability to place each new prompt in context and thereby make appropriate statements in response — even better than ChatGPT.
In the “Self-Controlled Memory system”, as it’s called, or SCM, the input a user types at the prompt is evaluated by a memory controller to see whether it requires dipping into an archival memory system called the memory stream, which contains all the past interactions between the user and the program. It’s rather like Wang and team’s SideNet and accompanying memory bank.
If memory is required, that collection of past input is accessed via a vector database tool such as Pinecone. The user’s input is a query, and it’s matched for relevance against what’s in the database.
Some user queries don’t require memory, such as “Tell me a joke”, which is a random request that any language model can handle. But a user prompt such as, “Do you remember the conclusion we made last week on the fitness diets?” is the kind of thing that requires access to past chat material.
In a neat twist, the user prompt, and the memory it retrieves, are combined, in what the paper calls “input fusion” — and it is that combined text that becomes the actual input to the language model on which it generates its response.
Also: This new AI system can read minds accurately about half the time
The end result is that the SCM can top ChatGPT in tasks that involve a reference back to hundreds of turns earlier in a dialogue, write Liang and team. They connected their SCM to a version of GPT-3, called text-davinci-003, and tested how it performed with the same input compared to ChatGPT.
In one series of more than 100 turns, consisting of 4,000 tokens, when the human prompts the machine to recall the hobbies of the person discussed at the outset of the session, “the SCM system provides an accurate response to the query, demonstrating exceptional memory-enhanced capabilities,” they write, while, “in contrast, it appears that ChatGPT was distracted by a considerable amount of irrelevant historical data.”
The work can also summarize thousands of words of long texts, such as reports. It does so by iteratively summarizing the text, which means storing the first summary in the memory stream, and then creating the next summary in combination with the previous summary, and so on.
The SCM can also make large language models that aren’t chat bots behave like chat bots. “Experimental results show that our SCM system enables LLMs, which are not optimized for multi-turn dialogue, to achieve multi-turn dialogue capabilities that are comparable to ChatGPT,” they write.
Both the Microsoft and the TikTok work can be thought of as extending the original intention of language models. Before ChatGPT, and its predecessor, Google’s Transformer, natural language tasks were often carried out by what are called recurrent neural networks, or RNNs. A recurrent neural network is a kind of algorithm that can go back to earlier input data in order to compare it to the current input.
Also: GPT-4: A new capacity for offering illicit advice and displaying ‘risky emergent behaviors’
The Transformer and LLMs such as ChatGPT replaced RNNs with the simpler approach — attention. Attention automatically compares everything typed to everything typed before, so that the past is always being brought into play.
The Microsoft and TikTok research work, therefore, simply extends attention with algorithms that are explicitly crafted to recall elements of the past in a more organized fashion.
The addition of memory is such a basic adjustment, it’s likely to become a standard aspect of large language models in future, making it much more common for programs to be able to make connections to past material, such as chat history, or to address the whole text of very long works.
[ad_2]
Source link